Claude Code 使用深度实践指南
Claude Code 使用深度实践指南
本文翻译自 Shrivu Shankar 的文章 How I Use Every Claude Code Feature,发布于 2025 年 11 月 2 日。这篇文章是最近我在使用Claude Code进行vibe coding的时候遇到的一些问题在寻找答案的时候发现的,对于一些相应的场景,比如为什么要避免 /compact,为什么自定义子智能体反而会带来问题,Skills 和 MCP 的真正定位是什么,文章做出了解释,分享了一些反直觉但是有效的方法。以下为原文。
我重度使用 Claude Code。
作为业余爱好者,我每周会在虚拟机(VM)中多次运行它来处理个人项目,通常会加上 --dangerously-skip-permissions 参数,以便快速实现脑中闪现的任何编码想法。在职业场景中,我所在团队的一部分成员负责构建面向全公司工程师的 AI-IDE(人工智能集成开发环境)规则与工具链,仅代码生成(codegen)一项每月就消耗数十亿 tokens。
CLI(命令行界面)代理工具领域正变得愈发拥挤。在 Claude Code、Gemini CLI、Cursor 和 Codex CLI 之间,感觉真正的竞争其实发生在 Anthropic 与 OpenAI 之间。但坦白说,当我与其他开发者交流时,他们的选择往往取决于一些看似表面的因素——某个“幸运”的功能实现,或是他们更偏好的系统提示词(system prompt)“氛围感”。到这个阶段,这些工具其实都相当好用了。我也感觉到,人们常常过度关注输出风格或用户界面。对我而言,“你完全正确!”这类谄媚式回应并非显著缺陷;它反而是一个信号,表明你过度介入了代理的工作流程。我的目标通常是“发射后不管”(shoot and forget)——委派任务、设定上下文,然后让它自主工作。评判工具的标准应是最终的 PR(Pull Request,拉取请求)质量,而非其实现路径。
在坚持使用 Claude Code 数月后,本文将分享我对 Claude Code 整个生态系统的思考。我们将覆盖我使用的几乎所有功能(以及同等重要的、我不使用的功能),从基础的 CLAUDE.md 配置文件、自定义斜杠命令(slash commands),到强大的子代理(Subagents)、钩子(Hooks)和 GitHub Actions 集成。本文篇幅较长,更适合作为参考文档而非一次性通读。
CLAUDE.md
在代码库中有效使用 Claude Code 时,最重要的单一文件是根目录下的 CLAUDE.md。该文件是代理的“宪法”,是其理解特定代码库工作方式的主要事实来源。
如何对待该文件取决于使用场景。对于个人项目,我允许 Claude 随意向其中写入内容。
对于职业工作,我们单体仓库(monorepo)的 CLAUDE.md 经过严格维护,当前大小为 13KB(我预计它很容易增长到 25KB):
- 仅记录被 30%(任意设定)及以上工程师使用的工具和 API(其他工具的文档放在产品或库专属的 Markdown 文件中)
- 我们甚至开始为每个内部工具的文档分配最大 token 数量,近乎于向团队“出售广告位”。如果你无法简洁地解释自己的工具,说明它尚未准备好进入
CLAUDE.md。
实践技巧与常见反模式
经过实践,我们形成了编写高效 CLAUDE.md 的强观点哲学:
从护栏(Guardrails)开始,而非手册CLAUDE.md 应从精简起步,仅记录 Claude 经常出错的地方。
避免 @-文件引用
如果其他地方已有详尽文档,很容易在 CLAUDE.md 中通过 @ 提及这些文件。但这会在每次运行时嵌入整个文件,导致上下文窗口膨胀。而如果仅提及路径,Claude 往往会忽略它。你必须向代理说明何时以及为何需要阅读该文件。例如:“对于复杂……用法或遇到 FooBarError 时,请参阅 path/to/docs.md 获取高级故障排查步骤。”
避免仅使用“禁止”类约束
避免纯否定性约束,如“Never use the –foo-bar flag”。当代理认为必须使用该标志时会陷入僵局。务必提供替代方案。
将 CLAUDE.md 作为强制简化机制
如果 CLI 命令复杂冗长,不要编写大段文档解释它们——这是在修补人类的问题。相反,编写具有清晰直观 API 的简单 bash 包装器并记录该包装器。尽可能保持 CLAUDE.md 简短,是简化代码库和内部工具链的绝佳强制机制。
以下是一个简化示例:
1 | |
最后,我们保持该文件与 AGENTS.md 同步,以维持与其他工程师可能使用的 AI IDE 的兼容性。
如需更多面向编码代理的 Markdown 编写技巧,参见《AI Can’t Read Your Docs》《AI-powered Software Engineering》和《How Cursor (AI IDE) Works》。
核心要点:将 CLAUDE.md 视为高层次、精心策划的护栏与指引集合。用它来指导你应在何处投入资源构建更友好的 AI(及人类)工具,而非试图使其成为全面手册。
紧凑化、上下文与清晰度
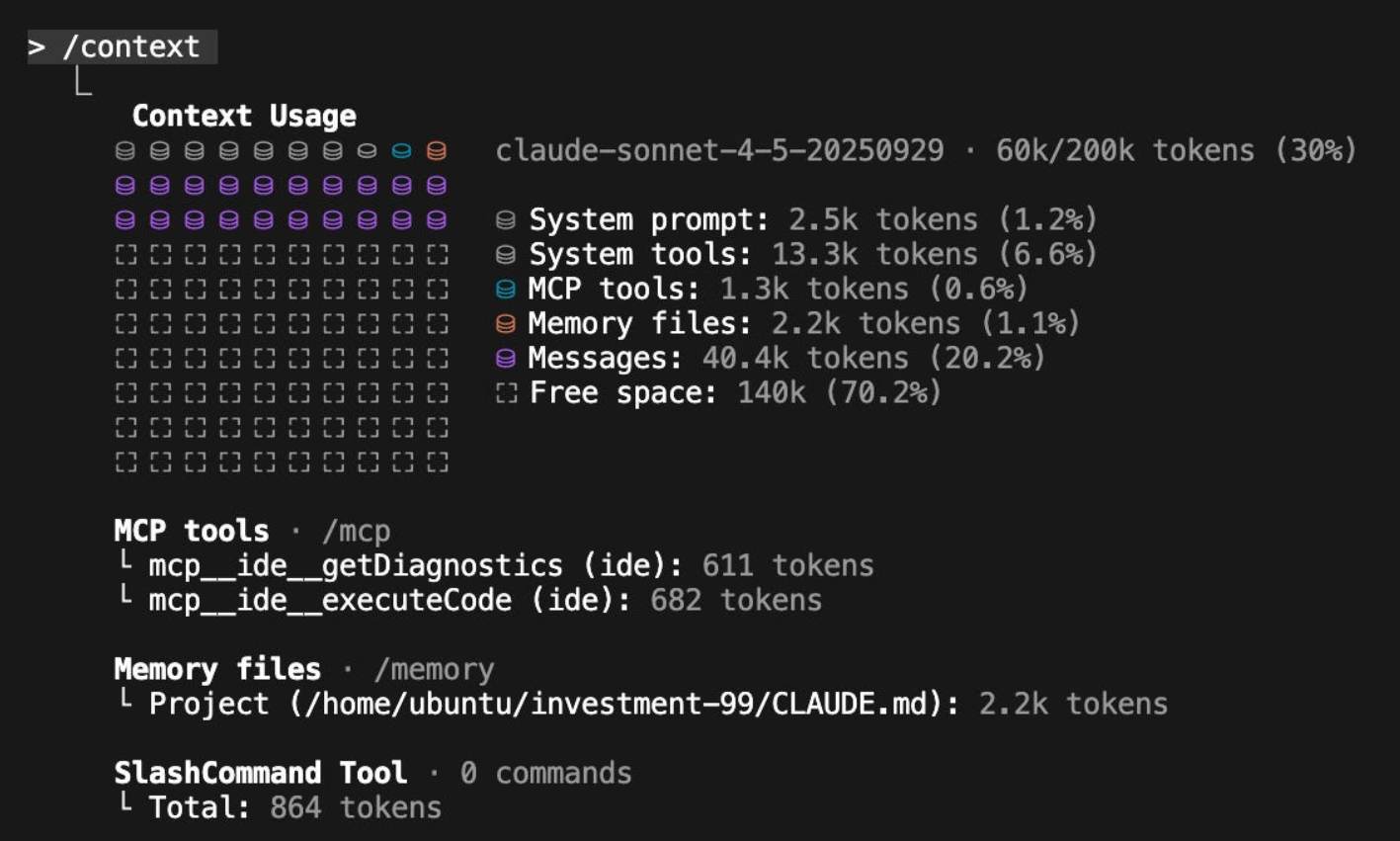
我建议在编码会话中至少运行一次 /context,以了解你如何使用 200k token 的上下文窗口(即使使用 Sonnet-1M,我也不完全信任整个上下文窗口能被有效利用)。对我们而言,在单体仓库中启动新会话的基础成本约为 20k tokens(10%),剩余 180k 用于实际变更——这部分消耗速度可能非常快。
我有三种主要工作流:
/compact(避免使用):我尽可能避免使用。自动紧凑化过程不透明、易出错且优化不足。/clear+/catchup(简单重启):我的默认重启方式。先/clear状态,然后运行自定义/catchup命令,让 Claude 读取当前 git 分支中所有变更文件。- “文档化并清除”(复杂重启):用于大型任务。让 Claude 将计划与进度导出至
.md文件,/clear状态后,启动新会话并告知其读取该.md文件继续工作。
核心要点:不要信任自动紧凑化。对简单重启使用 /clear,对复杂任务使用“文档化并清除”方法创建持久的外部“记忆”。
自定义斜杠命令(Custom Slash Commands)
我认为斜杠命令仅是常用提示词的简单快捷方式,仅此而已。我的配置极为精简:
/catchup:前文提及的命令,仅提示 Claude 读取当前 git 分支中所有变更文件。/pr:简单助手,用于清理代码、暂存并准备拉取请求。
依我之见,如果你维护着一长串复杂自定义斜杠命令列表,你已陷入反模式。对我而言,Claude 这类代理的核心价值在于:你可以输入几乎任何内容并获得有用、可合并的结果。一旦强迫工程师(或非工程师)学习一份文档化的新“魔法命令”列表才能完成工作,你就失败了。
核心要点:将斜杠命令用作简单的个人快捷方式,而非替代构建更直观的 CLAUDE.md 和更完善的代理工具链。
自定义子代理(Custom Subagents)
理论上,自定义子代理是 Claude Code 用于上下文管理的最强大功能。其理念很简单:复杂任务需要 X tokens 的输入上下文(例如如何运行测试),累积 Y tokens 的工作上下文,并产生 Z tokens 的答案。执行 N 个任务意味着主窗口中消耗 (X + Y + Z) * N tokens。
子代理方案是将 (X + Y) * N 的工作分派给专用代理,后者仅返回最终的 Z tokens 答案,从而保持主上下文清洁。
我发现它们在理念上强大,但实践中自定义子代理会引发两个新问题:
- 上下文隔离:如果我创建
PythonTests子代理,我就将所有测试上下文从主代理中隐藏。它无法再对变更进行整体推理,被迫调用子代理才能知晓如何验证自身代码。 - 强制人类工作流:更糟的是,它们强迫 Claude 遵循刚性的人类定义工作流。我实际上在规定它必须如何委派任务——而这正是我试图让代理为我解决的问题。
我偏好的替代方案是使用 Claude 内置的 Task(...) 功能派生通用代理的克隆体。
我将所有关键上下文放入 CLAUDE.md,然后让主代理自主决定何时以及如何将工作委派给自身副本。这使我获得子代理的上下文节省优势,同时避免其缺陷。代理可动态管理自身编排。
在我《构建多代理系统(第二部分)》一文中,我将此称为“主-克隆”(Master-Clone)架构,并强烈偏好它而非自定义子代理鼓励的“主-专家”(Lead-Specialist)模型。
核心要点:自定义子代理是脆弱的解决方案。为主代理提供上下文(在 CLAUDE.md 中),并让它使用自身的 Task/Explore(...) 功能管理委派。
恢复、继续与历史(Resume, Continue, & History)
基础层面,我频繁使用 claude --resume 和 claude --continue。它们非常适合重启故障终端或快速恢复旧会话。我常会 claude --resume 数天前的会话,仅为了询问代理如何克服特定错误,然后利用该信息改进我们的 CLAUDE.md 和内部工具链。
更深入地,Claude Code 将所有会话历史存储在 ~/.claude/projects/,以便访问原始历史会话数据。我编写了脚本对这些日志进行元分析,寻找常见异常、权限请求和错误模式,以帮助改进面向代理的上下文。
核心要点:使用 claude --resume 和 claude --continue 重启会话并挖掘埋藏的历史上下文。
钩子(Hooks)
钩子至关重要。个人项目中我不使用它们,但在复杂企业仓库中,它们对引导 Claude 至关重要。它们是确定性的“必须执行”规则,补充 CLAUDE.md 中的“应当执行”建议。
我们使用两类钩子:
- 提交时阻断钩子(Block-at-Submit Hooks):我们的主要策略。我们有一个
PreToolUse钩子,包装任何Bash(git commit)命令。它检查/tmp/agent-pre-commit-pass文件(仅当所有测试通过时,我们的测试脚本才会创建该文件)。若文件缺失,钩子将阻断提交,迫使 Claude 进入“测试-修复”循环直至构建通过。 - 提示钩子(Hint Hooks):简单的非阻断钩子,当代理执行次优操作时提供“即发即忘”式反馈。
我们刻意不使用“写入时阻断”钩子(例如在 Edit 或 Write 时)。在代理计划中途阻断会使其困惑甚至“沮丧”。更有效的方式是让它完成工作,然后在提交阶段检查最终完成结果。
核心要点:使用钩子在提交时(block-at-submit)强制状态验证。避免在写入时阻断——让代理完成计划,再检查最终结果。
规划模式(Planning Mode)
对于 AI IDE 中的任何“大型”功能变更,规划必不可少。
个人项目中,我 exclusively 使用内置规划模式。这是在 Claude 开始工作前与其对齐的方式,既定义构建方法,也设定“检查点”——代理需在此暂停并向我展示工作成果。定期使用此功能可培养直觉:了解获得良好规划所需的最小上下文,同时避免 Claude 搞砸实现。
在工作单体仓库中,我们开始基于 Claude Code SDK 推出定制规划工具。它类似原生规划模式,但经过强提示词引导,使其输出与我们现有的技术设计格式对齐。它还开箱即用地强制执行内部最佳实践——从代码结构到数据隐私与安全。这使工程师能像资深架构师一样“氛围感规划”(vibe plan)新功能(至少这是宣传点)。
核心要点:对复杂变更始终使用内置规划模式,在代理开始工作前对齐计划。
技能(Skills)
我赞同 Simon Willison 的观点:Skills(技能)可能比 MCP(Model Context Protocol,模型上下文协议)更重要。
如果你关注过我的文章,会知道我已从多数开发工作流中远离 MCP,转而偏好构建简单 CLI(如我在《AI Can’t Read Your Docs》中论证的)。我对代理自主性的心理模型已演进为三个阶段:
- 单次提示(Single Prompt):在单一大型提示词中提供所有上下文。(脆弱,不可扩展)
- 工具调用(Tool Calling):“经典”代理模型。我们手工制作工具并为代理抽象现实。(更好,但创建新抽象和上下文瓶颈)
- 脚本化(Scripting):我们向代理开放原始环境——二进制文件、脚本和文档——它即时编写代码与之交互。
在此模型下,Agent Skills 是显而易见的下一功能。它们是“脚本化”层的正式产品化。
如果你像我一样已偏好 CLI 而非 MCP,你其实一直在隐式享受 Skills 的优势。SKILL.md 文件仅是以更结构化、可共享和可发现的方式记录这些 CLI 与脚本,并向代理暴露它们。
核心要点:Skills 是正确的抽象。它们将基于“脚本化”的代理模型正式化,该模型比 MCP 所代表的刚性类 API 模型更健壮灵活。
MCP(Model Context Protocol,模型上下文协议)
Skills 并不意味着 MCP 已死(另见《Everything Wrong with MCP》)。此前,许多人构建了糟糕的、上下文繁重的 MCP,包含数十个仅镜像 REST API 的工具(read_thing_a(), read_thing_b(), update_thing_c())。
“脚本化”模型(现由 Skills 正式化)更优,但它需要安全访问环境的方式。在我看来,这是 MCP 的新聚焦角色。
MCP 不应是臃肿的 API,而应是简单安全的网关,提供少量强大高层工具:
download_raw_data(filters…)take_sensitive_gated_action(args…)execute_code_in_environment_with_state(code…)
在此模型中,MCP 的职责不是为代理抽象现实;其职责是管理认证、网络和安全边界,然后退居幕后。它提供代理入口点,代理随后利用其脚本和 Markdown 上下文完成实际工作。
我仍在使用的唯一 MCP 是 Playwright 相关的——这很合理,因其是复杂的状态化环境。我所有无状态工具(如 Jira、AWS、GitHub)均已迁移至简单 CLI。
核心要点:使用充当数据网关的 MCP。向代理提供一两个高层工具(如原始数据转储 API),供其进行脚本化操作。
Claude Code SDK
Claude Code 不仅是交互式 CLI,也是构建全新代理(面向编码与非编码任务)的强大 SDK(Software Development Kit,软件开发工具包)。对于多数新个人项目,我已将其作为默认代理框架,取代 LangChain/CrewAI 等工具。
我主要在三方面使用它:
- 大规模并行脚本化:对于大型重构、缺陷修复或迁移,我不使用交互式聊天。我编写简单 bash 脚本,以并行方式调用
claude -p "in /pathA change all refs from foo to bar"。这比让主代理管理数十个子代理任务更具可扩展性和可控性。 - 构建内部聊天工具:SDK 非常适合将复杂流程封装为面向非技术用户的简单聊天界面。例如一个安装程序,出错时回退至 Claude Code SDK 为用户直接修复问题;或一个内部“v0-at-home”工具,让设计团队在自有 UI 框架中“氛围感编码”前端模拟界面,确保其想法高保真且代码可直接用于前端生产。
- 快速代理原型设计:这是我最常用的场景。不限于编码。若我对任何代理任务有想法(例如使用自定义 CLI 或 MCP 的“威胁调查代理”),我会用 Claude Code SDK 快速构建并测试原型,再决定是否投入完整部署架构。
核心要点:Claude Code SDK 是强大通用的代理框架。将其用于代码批处理、构建内部工具,以及在采用更复杂框架前快速原型化新代理。
Claude Code GHA(GitHub Action)
Claude Code GitHub Action(GHA,GitHub 动作)可能是我最喜爱却最被低估的功能之一。概念很简单:仅在 GHA 中运行 Claude Code。但正是这种简洁性赋予其强大能力。
它类似 Cursor 的后台代理或 Codex 托管 Web UI,但可定制性更强。你控制整个容器与环境,获得更丰富的数据访问权限,以及关键的更强沙箱化与审计控制——这是其他产品无法提供的。此外,它支持所有高级功能如 Hooks 和 MCP。
我们用它构建了定制“任意位置 PR”工具。用户可从 Slack、Jira 甚至 CloudWatch 告警触发 PR,GHA 将修复缺陷或添加功能并返回完全测试过的 PR。
由于 GHA 日志即完整代理日志,我们建立了运维流程,在公司层面定期审查这些日志,识别常见错误、bash 异常或未对齐的工程实践。这创建了数据驱动的飞轮:缺陷 → 改进的 CLAUDE.md/CLI → 更优代理。
1 | |
核心要点:GHA 是 Claude Code 操作化的终极方式。它将 Claude Code 从个人工具转变为工程系统中可审计、自改进的核心组件。
settings.json
最后,我发现以下 settings.json 配置对个人与职业工作均至关重要:
- **
HTTPS_PROXY/HTTP_PROXY**:调试时极佳。我用它检查原始流量,精确查看 Claude 发送的提示词。对于后台代理,它也是细粒度网络沙箱化的强大工具。 - **
MCP_TOOL_TIMEOUT/BASH_MAX_TIMEOUT_MS**:我调高了这些值。我喜欢运行长时复杂命令,默认超时往往过于保守。鉴于 bash 后台任务现已支持,我不确定这是否仍必要,但为防万一仍保留。 - **
ANTHROPIC_API_KEY**:工作中我们使用企业 API 密钥(通过apiKeyHelper)。这使我们从“按席位”许可转向“按用量”定价,更契合我们的工作模式:- 它考虑了开发者用量的巨大差异(我们观察到工程师间存在 1:100 倍差异)
- 它允许工程师在单一企业账户下试验非 Claude Code LLM 脚本
- **
"permissions"**:我偶尔会自我审计已授权 Claude 自动运行的命令列表。
核心要点:settings.json 是高级定制的强大场所。
结语
内容很多,但希望对你有用。如果你尚未使用 Claude Code 或 Codex CLI 等基于 CLI 的代理工具,你或许应该尝试。这些高级功能鲜有优质指南,唯一学习途径就是深入实践。